Retrieve PDF Metadata#
Users new to Zotero may find the prospect of importing all their data somewhat daunting. Many researchers already have a large collection of PDFs that they’ve previously organized manually. Zotero makes it easy to import these PDFs and retrieve full bibliographic metadata (for searching, citing, indexing, and organizing), taking much of the pain out of switching.
To use this feature, simply drag your existing PDFs into your Zotero library or use the “Store Copy of File” or “Link to File” options from the add new item menu (green plus sign). By default, Zotero will automatically retrieve metadata for each PDF, create an appropriate parent item, and rename the associated file based on the metadata. (You can disable these automatic functions in the General pane of Zotero preferences.)
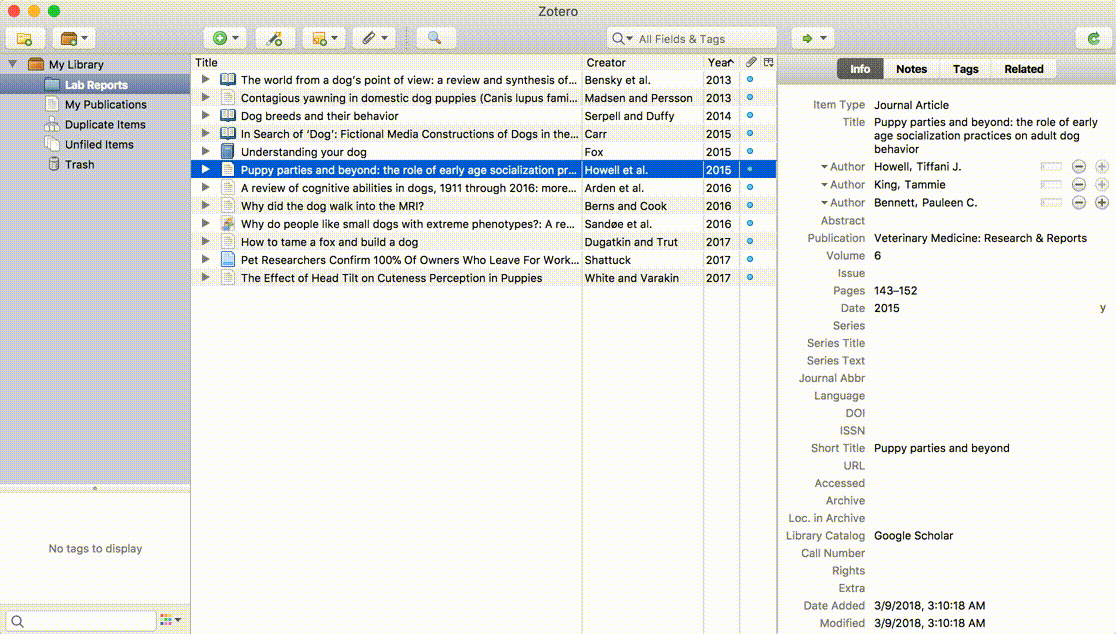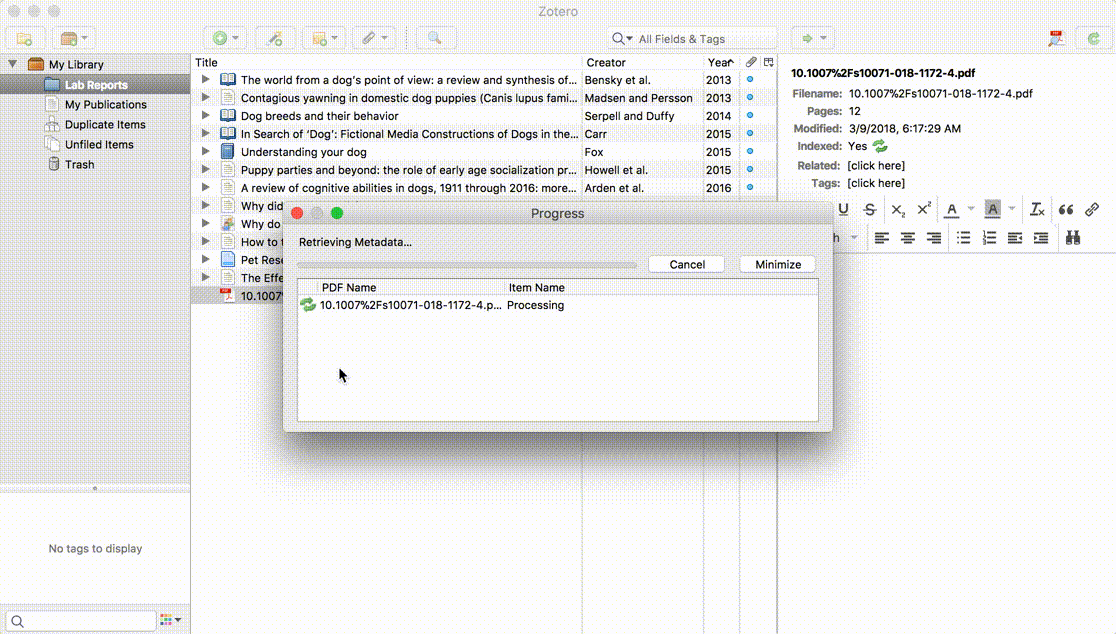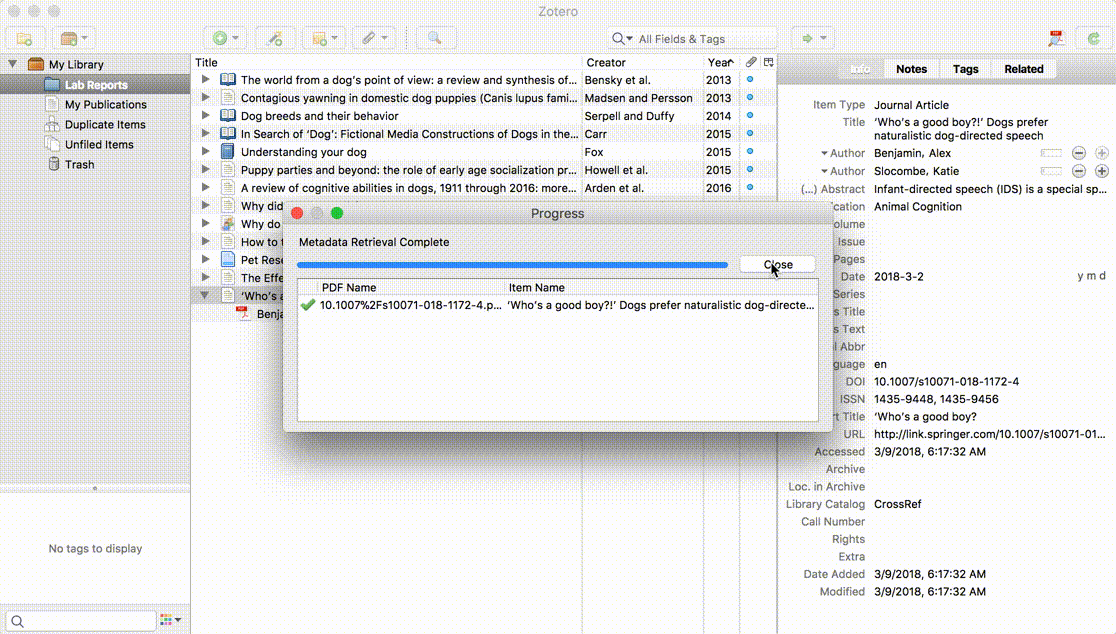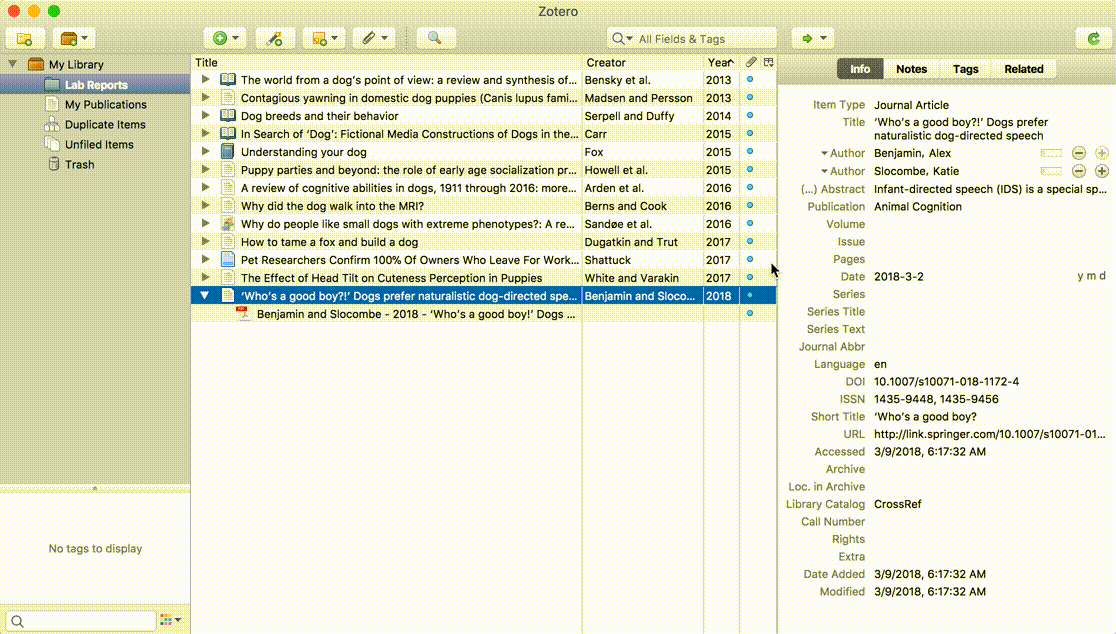
If Zotero can find a match for the PDF, it will create a full Zotero item with the available data and attach the PDF. If it can’t, it will leave the PDF as a standalone attachment, allowing you to add a parent item another way — either by saving an item from the web and dragging the PDF on top of it or by right-clicking on the PDF, choosing Create Parent Item, and entering an identifier such as a DOI or ISBN. If all else fails, you can click Manual Entry after selecting Create Parent Item and manually enter metadata for the item.
If you’re not happy with the metadata saved for the PDF, you can right-click on the new parent item and choose Undo Retrieve Metadata to leave the PDF as a standalone attachment for further manual processing.
Zotero should retrieve high-quality metadata for most academic PDFs. While it can sometimes extract basic information (title, author) from other documents, you shouldn’t expect that — anything can be distributed as a PDF, but that doesn’t mean there’s any standard metadata available for it.
Note: While this feature can greatly facilitate importing large existing libraries of PDFs, it is not the best way to add items to your library in general. Items and PDFs can be imported faster by using the Zotero Connector plugin in your browser from the article pages (not the PDFs) of publisher websites or most scholarly databases. This saves several steps versus downloading the PDF manually and adding it to Zotero. The item metadata will also often be higher quality. See Adding Items to Zotero for more info.
How It Works#
The Retrieve Metadata feature uses a Zotero web service to find item metadata. The Zotero client sends the first few pages of text from the PDF to the web service, which uses a variety of extraction algorithms and known metadata from Crossref, paired with DOI and ISBN lookups, to build a parent item for the PDF. The Zotero lookup service doesn’t require a Zotero account and doesn’t log any data about the content or results of searches.